
April 21, 2023
There are many stories about people (with various viewpoints) criticizing generative AI like language models (well, the model creators, the model's just an equation applied to some data) for having biases or "worldview" that they don't agree with. I'd argue that every interesting person has opinions, and its not any different for a ML model. But there's a time and a place for everything - having an e-commerce FAQ that also shares its political views wouldn't be appropriate (though people do stuff like that too, way too often). Here I share a framework for thinking about how a generative AI model should be constrained. And I also argue that the current crop is tending towards the least interesting "politician" personality in the pursuit of trying not to be controversial.
I’ve seen various criticisms of the behavior of chatGPT and related technologies: one one hand, there are claims that it will say inappropriate things (for some value of inappropriate) and on the other, there are various acusations of political bias or partial censorship of controversial views. The same sorts of criticisms can be applied to other generative models, such as stable diffusion that generates images from text. A simplified criticism of inappropriateness might be that it perpetuates stereotypes from its training data. On the censorship side, I personally removed the content filter from my version of SD when images I generated of metal parts kept getting censored out if they were remotely “suggestive” (for example an image of two washers were side by side triggered the initial content filter they imposed, and I couldn’t generate images like the one below).
Almost all the criticism I’ve seen occur in a near vacuum, where the main intent seems to be to get the model to do something you can criticise. When it comes to actual uses of generative models, there is going to be some tradeoff between how “safe” the model is, and how interesting it’s output is. One way to think about this is along the axes shown below. The plot shows “content” along the x-axis, meaning how much information the model is providing. And “controversy” on the y-axis, meaning roughly how likely it is that everyone would agree with or be satisfied by the output.
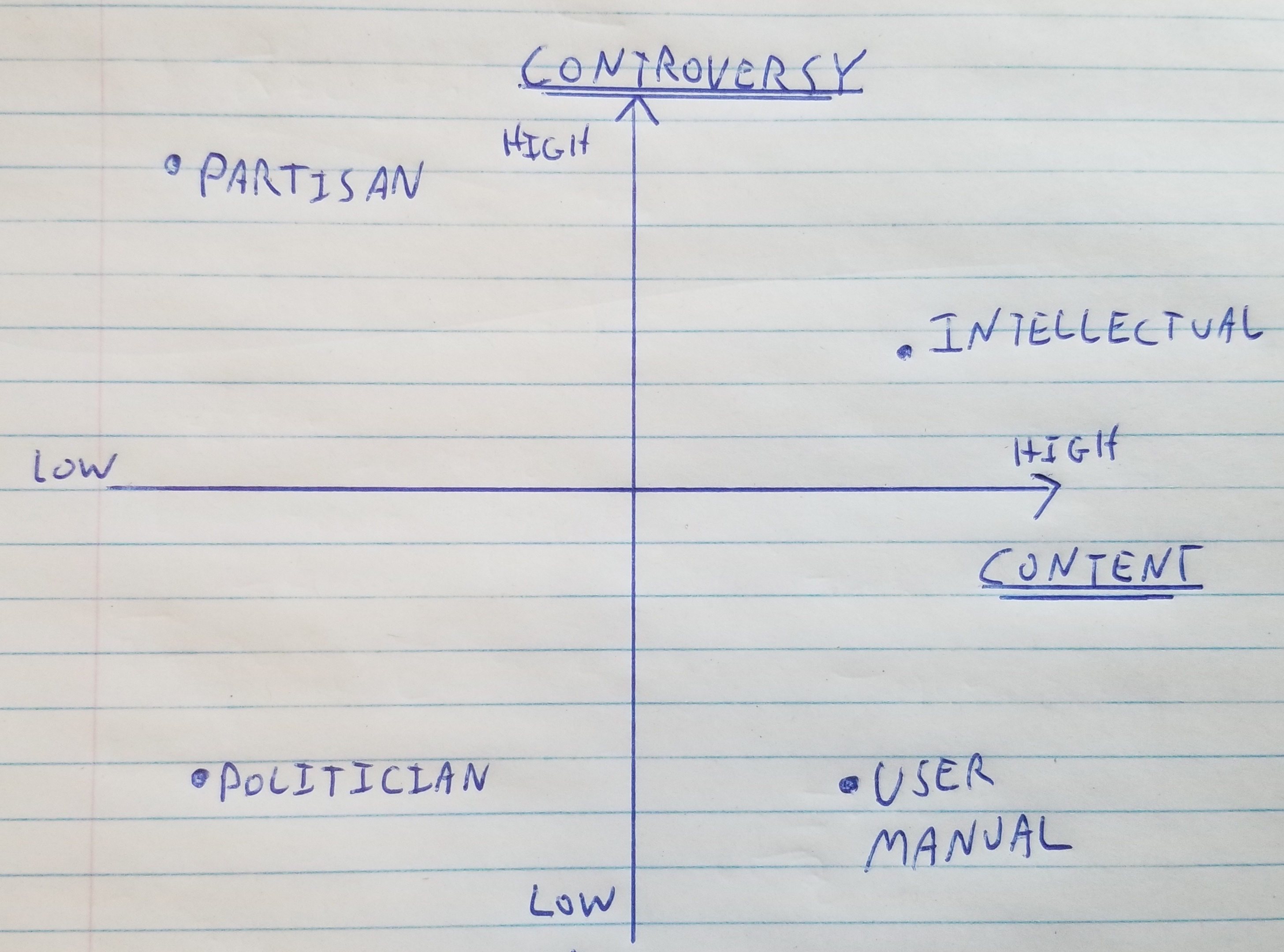
The most “safe” applications are what I call “user manual” on the chart. This would be an application where a LLM was used to provide information about how to use a product or service - “how do I set the time on my microwave?” This is probably the most common application I’ve seen so far, for example there are various aides that can help write computer programs. In these applications, there can be lots of information, and it’s all just facts about how something works, so there’s not any room for controversy (aside from some obscure technical debates - I’m sure there’s someone who will get angry when Github co-pilot doesn’t use strong typing).
It’s easy to go downhill from here. Consider an application with low information and high controversy. This is what I call “partisan” - essentially a mouthpiece for one side’s talking points. You can probably picture such content from other social media platforms. And to be fair (even if nobody would be agree to be labelled this way) there can be some value to this kind of content, for example if a political party or advocacy group wants to share it’s political platform or generate promotional content. The important distinction I’d draw in a partisan “bot” is that it’s not really there to debate or consider other sides, it’s just there to deliver a message.
Potentially most interesting (and obviously with a biased label) is what I call “intellectual”. This is a generative model that constructs “opinions” (it’s just a computer program, it doesn’t really have opinions) and could operate more as a conversation partner than just an information source. This model falls in the high content, high controversy side. It’s not possible to have interesting, considered opinions on many topics that everyone is going to agree with. But such opinions will lead to the most engaging conversations, and may be more persuasive. There’s an analogy here to the idea that the level of analysis in news reporting correlates with bias, as in the chart below (which I don’t really endorse but agree with the concept that analysis requires a choice of lens).
A computer program that can be interrogated endlessly on it’s “views” is going to have accusations of bias leveled at it. This kind of model is only really appropriate when those deploying it can be thick skinned and not worry about controversy. This could be true for think tanks, universities, or other institutions that are more interested in intellectual debate than only sharing “safe” opinions. There will always be somebody left disagreeing with opinionated views, however this would be the kind of model you’d want to chat with if you were stuck on an island.
Then there is the “politician” (in the F. Scott Fitzgerald or Isaac Asimov sense, not the partisan) that says nothing controversial by saying long platitudes that amount to nothing. This unfortunately seems to be the trend in popular language models like chatGPT, that appear to get reactively constrained as people find ways to make them say controversial things. Such models are almost certainly the least useful, in proportion to their level of restraint, as they only really achieve the aim of not trying to rock the boat, without providing any real intellectual value. Better to just respond with an empty string than some bromide. I think this has come to be the default because of the current one-size-fits-all api approach that’s been used to deploy the models. Manuals are boring, partisans are transparently biased, intellectualism requires opinions, so we’re left with attempts at a political solutions that appeases the majority. This can change as models get tailored to real applications and configures into more useful modes.
The framework does not address intentional “hacking” where someone deliberately gets a model to do something inappropriate. If that’s the only failure mode a model has, I don’t think it’s very interesting. You could achieve the same effect without the model by just typing whatever inappropriate statement yourself. And then there is “hallucinating” or more accurately, the output of the autocomplete being false in some way. That can impact all the categories I’ve mentioned above and requires its own checks and balances.
Content vs controversy can be a simple way to think about how you want to constrain the behavior of a model so that it achieves its aims without causing trouble on the side. User manuals and partisans should stick to their scripts, and be there to deliver facts and talking points respectively, being cut off before straying into the realm of opinion. Intellectuals should not be censored (which in any event gets circumvented) but would be better to focus on consistency and quality of their opinions. And they should be cut some slack, in that it’s going to be possible to force such systems into saying things universally considered inappropriate - these are still actively being developed and researched, and are not sentient or intentioned, so when one says something “bad” when pressed, it’s not a sign of some deeper pathology. And politicians are pointless.
Andrew Marble
andrew@willows.ai