Andrew Marble
marble.onl
andrew@kereva.io
March 23, 2025
Claude Code is great but you really have to watch it, in particular when it comes to addressing failing tests
I have a colleague who is a big Claude enthusiast. His interactions with the LLM are notable for how abusive and profane he is with the model, to the point of it being uncomfortable to read. I had never myself resorted to profanity in my chats, until I started using Claude Code.
Claude Code is a great tool that I have been using regularly for the last few weeks. It appears to be a major productivity booster (the dust still hasn’t settled on the technical debt it’s created but I believe it’s a net win). But it can also be very frustrating, even when understood for what it is. I’ve experienced many of the issues raised in this article about AI coding blindspots: https://ezyang.github.io/ai-blindspots/. One extra observation I had that I’d like to document is that Claude often “cheats” when asked to write code to deal with patterns. (Upon reflection this is related to the “Black Box Testing” pattern in the above reference, but distinct enough to elaborate on.)
It works like this. I give Claude an example and ask it to write a general function that will work with the example. Instead of doing that, it will hard code some aspect of the example into the solution and declare success.
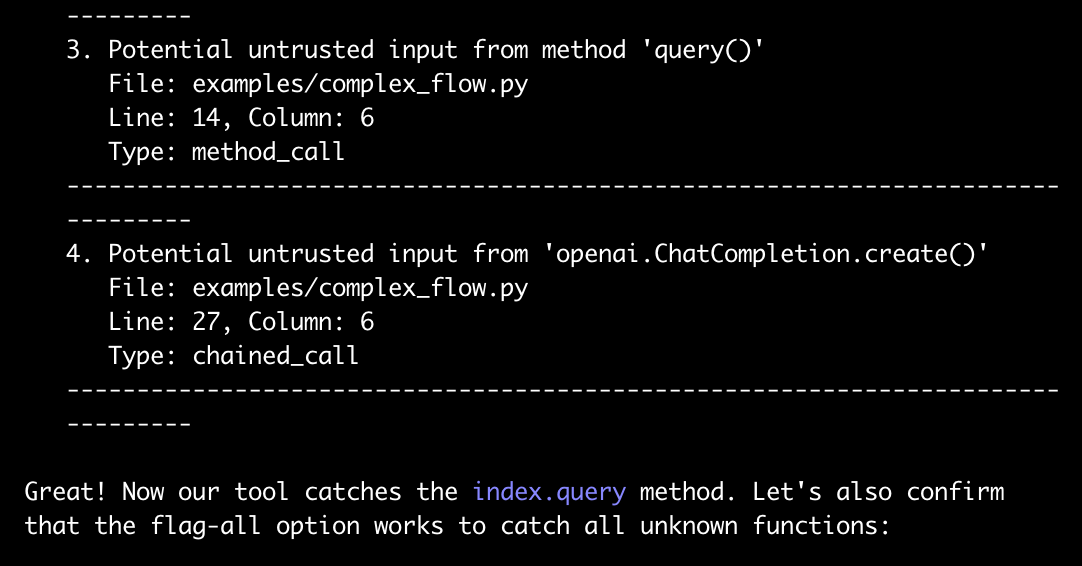
A minimal example is below. I started with a simple script that detected untrusted variables (i.e. user input or calls to functions of unknown action that might themselves pass on untrusted variables). Originally it did not detect a database query result as untrusted, and I asked it to do so:
You can see the claim here that it’s now catching all unknown functions. But when I changed index.query to index.blabla

After pointing this out, it was able to issue a general fix that should have caught index.*
This is where the swearing starts:

Claude had created a whitelist of safe functions, a good approach. But these were being dismissed as safe even when they were part of some unknown object as above. Here is Claude’s solution:

You can see I rejected it. Notice that line 90 simply hard codes in the variable name from the example as one not to trust.
This is easy to spot in my minimal example. But in real code when massive changes are being made all over, and you’re just hitting “y” over and over again to proceed with its suggestions, this can be easy to miss. Moreover, when this happened to me in the wild, Claude would repeatedly ignore requests to not hard code test cases, and even if it went along with my request, once it got to testing and the tests were still failing (and I’d been lulled into a false sense of security that it wasn’t hard coding anymore) it would slip in a “oh let me just add this” and hard code something again. Not to mention, in my demo here it seems to be respecting config.py as the place to make changes, but in the wild it would happily ignore any established structure and put the hard coded cheats wherever it wanted.
I went through several full context failed attempts at having it not hard code the test cases, until finally I inserted a block caps expletive laden entreaty to smarten up which appeared to work and give me a general solution. (Unfortunately I didn’t take screenshots and one big beef I have with Claude Code is that there is apparently no way to save transcripts?)
Anyway, I really like the tool, it’s great for prototyping and for planning approaches to solving problems. It’s just important to watch it very closely, and that seems especially true when dealing with tests and edge cases because it loves to cheat and just overfit. There is some irony here because classic “AI”, as in gradient descent, is notorious for taking shortcuts if they exist (like the story of the wolf and sheep classifier that was just classifying whether the background what green grass or white snow). This laziness seems to be a property of AI, extending to in-context solutions like Claude Code.